
In this blog, I’ll introduce our LREC 2022 paper, with the focus on quotations, quotation extraction and quotation attribution tasks. This topic is highly related to fact-checking, media monitoring and news tracking.
What is a quotation anyway?
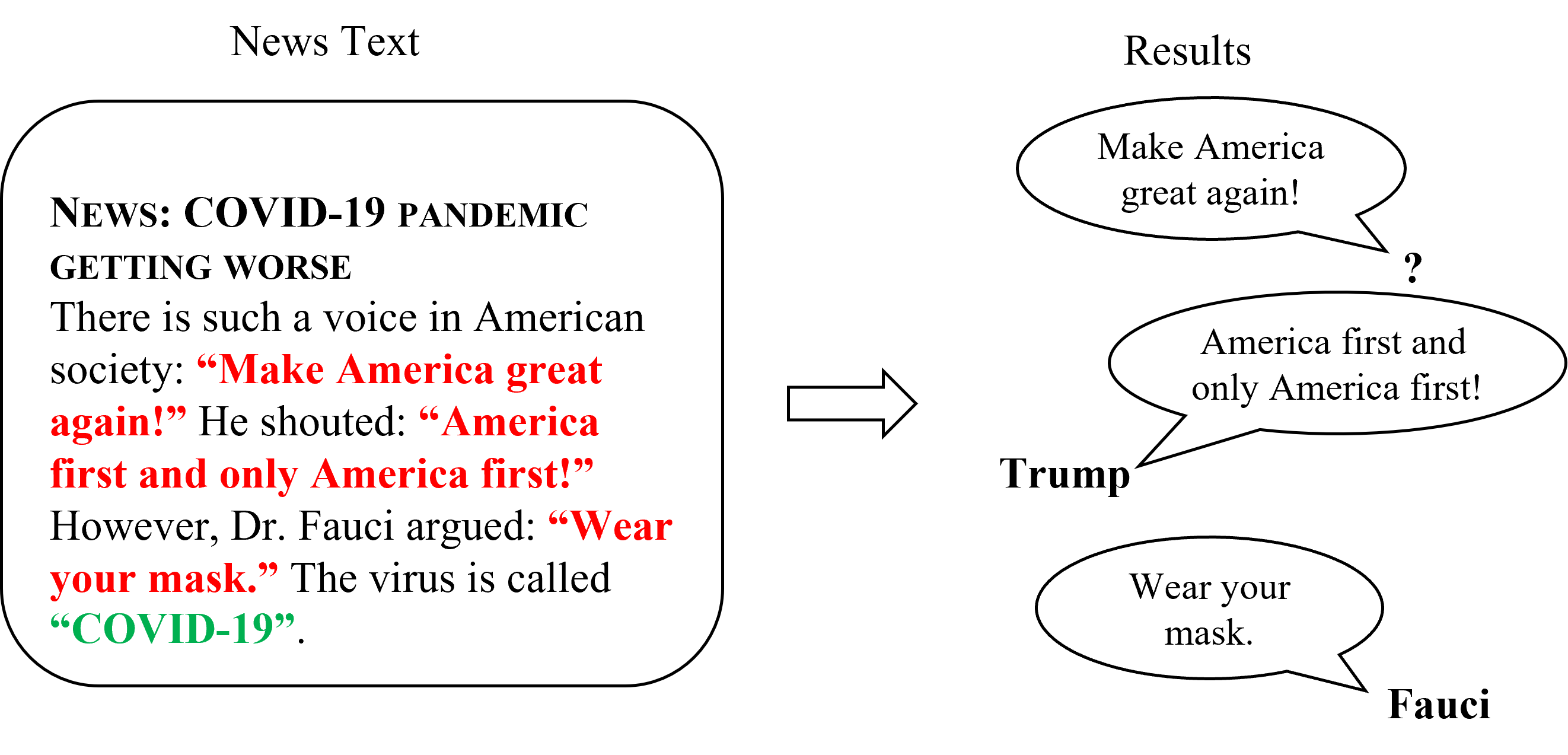
As shown in the figure above, A quotation is a general notion that covers different kinds of speech, thought, and writing in text. It is a prominent linguistic device for expressing opinions, statements, and assessments attributed to the speaker. Concretely, there are three types of quotations: direct quotations, indirect quotations and mixed quotations. Among all kinds of quotations, the entire content of the direct quotation is in quotation marks, which means that what the speaker said is transcribed verbatim.
Direct quotations are of considerable sigificance among all types of quotations. On the one hand, news writers attribute direct quotations to speakers, making claims credible and authoritative, leading to more traceable and informative news. These direct quotations from politicians, public figures, and other celebrities improve the authenticity and fairness of news, making news more convincing. On the other hand, the development of social media and advanced language generation models, such as GPT, has led to the proliferation of fake news.
Besides news writing, direct quotations are also actively involved in various NLP tasks. Since direct quotations are high subjective opinions, cognitions and assertions, they are used in opinion mining and claim detection task to discover opinions, sentiment analysis task to evaluate the author’s mood, fact check task to verify factual information, statement monitoring task to track others’ speech. Many websites apply these tasks. For example, NewsBrief is a website that automatically extracts and attributes quotations, detects events, and updates them in real-time. Another website, Politifact, tracks the statements of politicians for news fact-checking to reduce misinformation. ISideWith tracks political views on different topics to boost voter engagement and education. However, these systems rely heavily on costly and time-consuming human labor.
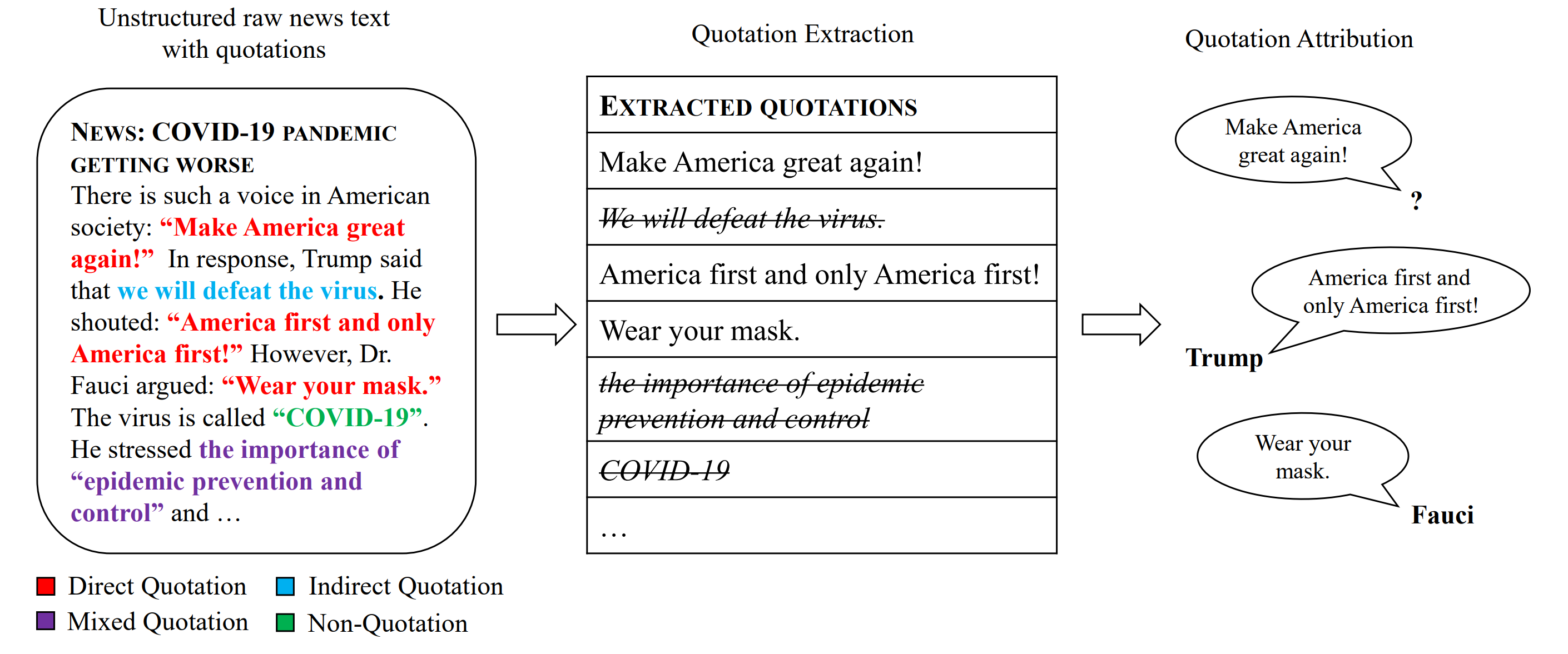
In general, as shown above, the above applications include two types of tasks related to quotations. The first task is called quotation extraction that refers to determining the span that represents the quotation in the document. The second task, quotation attribution, refers to determining the speaker of the quotation. It is one of the primary criteria for maintaining integrity in journalism as a primary rhetorical mechanism to promote the veracity and correctness of reporting.
Our solution
To alleviate the above problems, we introduce a corpus of direct quotations called DirectQuote. To build the corpus, we continuously sample news from multiple news sources to keep the text distribution in the corpus consistent with that in real applications. We select 19,706 paragraphs containing quotation marks, and annotate 10,279 quotations and corresponding speakers. When annotating speakers, we ensure that valid speakers should be linked to a person entity in a named entity library. Among them, simple patterns are removed to increase the diversity of the corpus.

This figure shows the flowchart of constructing the corpus. We hope that the quotations in the corpus are diverse and can be applied in various downstream tasks such as stance analysis and sentiment analysis. Therefore, we select representative and multiple news sources across the political spectrum, including 13 well-known online news media from five major English-speaking countries. After pre-processing, we build the DirectQuote corpus to apply neural methods on quotation extraction and quotation tasks.
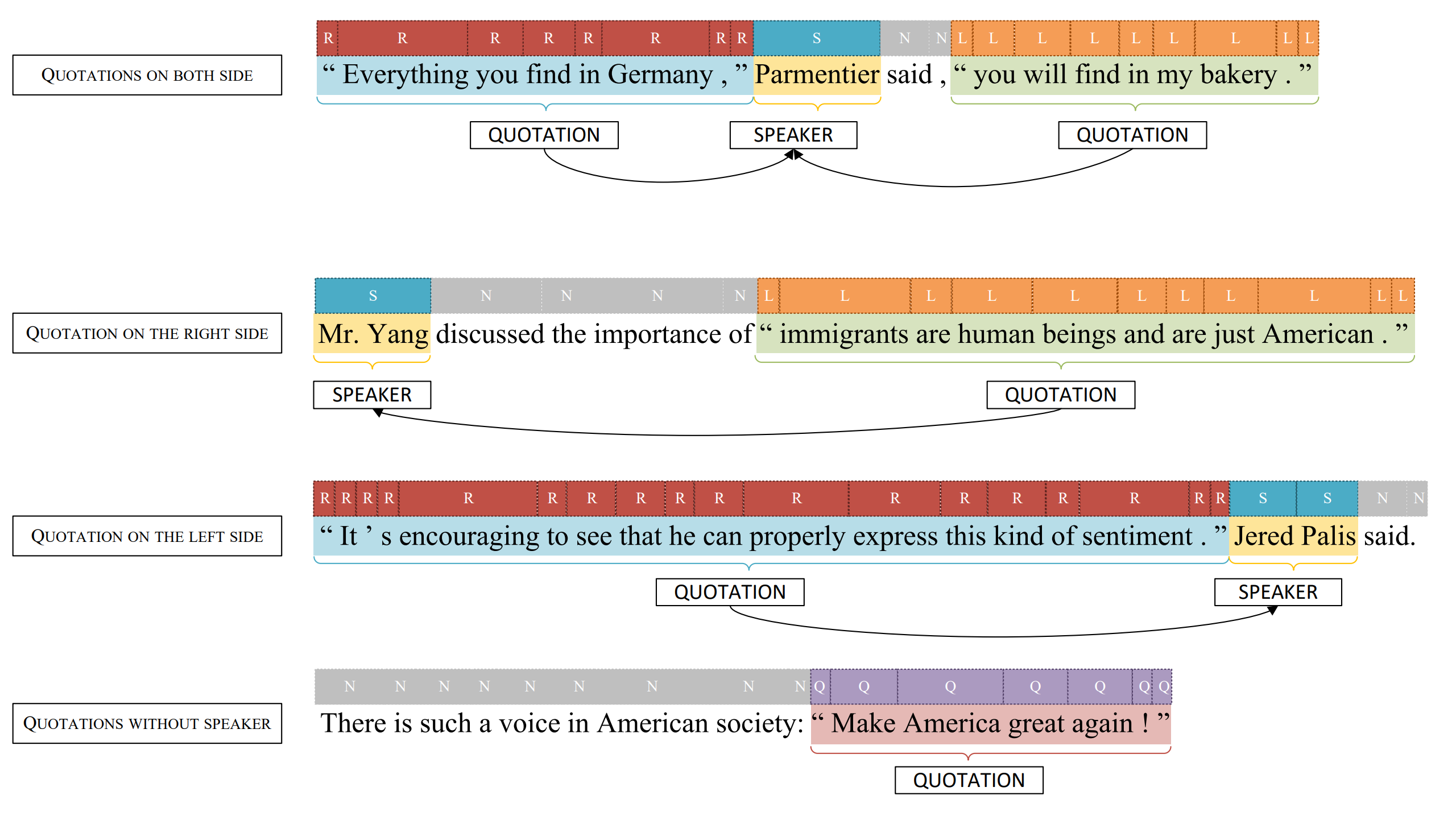
Although the common rule-based method is fast and performs well in the cases of simple syntax, it cannot handle rare quotation patterns.
We decide not to adopt the common pipeline design where separate models are designed to solve quotation extraction and attribution tasks, and additional models are introduced for named entity recognition and dependency analysis during preprocessing. Multiple pipeline stages increase the cumulative error and increase the time and space cost of the model, which is not suitable for scenarios with massive amounts of data.
Instead, an end-to-end sequence annotation model is designed to perform quotation extraction and attribution tasks simultaneously. Our model takes the original text as input and directly predicts the quotation and speaker. As shown above, the model not only outputs the span of the quotation and speaker, but also determines the correspondence between the quotation and speaker by predicting the speaker’s direction relative to the quotation. Thus, neural models could be fine-tuned to maximize the log-likelihood of the output corresponding to the ground-truth label using the cross-entropy loss.
Results
Almost all models have F1 scores of 70% or higher in the quotation extraction and attribution tasks. This proves that it is feasible to model the joint task of quotation extraction and attribution as a sequence labeling task. By adding a CNN layer or a CRF layer, the feature extraction ability of LSTM is improved, which increases the overall recall rate by approximately 3%-6%. Because BERT is pre-trained on a large number of corpora, and the Transformer model can effectively extract different levels of semantic and grammatical features, the BERT model has stronger accuracy and generalization capabilities, and outperforms other models by approximately 5% absolute precision and recall of the speaker.
What’s next?
Based on our work, potential future research directions include but are not limited to increasing the scale of the dataset, extracting mixed quotations and indirect quotations, and applying the dataset to large-scale automatic extraction and attribution systems.
Contact
For further discussion, please contact Yuanchi Zhang (yuanchi-21@mails.tsinghua.edu.cn)