
In recent years, there has been an increasing interest in moving AI applications, such as Neural Machine Translation (NMT), from cloud to mobile devices. Compared with cloud-based NMT services, on-device NMT systems offer increased privacy, low latency, and a more compelling user experience.
However, it is challenging to deploy NMT models on edge devices. Due to high computation costs, on-device NMT systems face a trade-off between latency and performance. Figure 1 gives an illustration of the latency, performance, and capacity of Transformer models with different hidden sizes when translating a sequence with 30 tokens on a Raspberry Pi 4 device. As we can see, a Transformer-base model takes over 5 seconds to translate a sequence of 30 tokens and such long latency is not desired for real-time applications. Although the latency can be reduced by simply scaling down the hidden size of the network, it also weakens the model’s capacity, making the translation performance of on-device NMT models far from satisfactory. How do we deploy NMT models on a Raspberry Pi 4 with high inference efficiency? We answer this question in our paper and introduce our work in this blogpost.

Model capacity is a key factor in determining the performance of neural networks. Therefore, how to increase the capacity of on-device NMT models without sacrificing efficiency is an important problem for achieving a better trade-off between latency and performance. Conditional computation, which proposes to activate parts of a neural network in an input-dependent fashion, is a representative method for improving model capacity without a proportional increase in computation time. Unfortunately, how to use conditional computation to improve model capacity without sacrificing efficiency still remains a major challenge for on-device NMT.

To address this challenge, we propose to use dynamic multi-branch (DMB) layers for on-device NMT. As shown in Figure 2, a dynamic multi-branch layer is capable of dynamically activating a single branch using an input-sensitive gate, enabling the resulting NMT model to have increased capacity thanks to the use of more branches while keeping the same efficiency with the standard single branch model.
Dynamic Multi-Branch Layers
Similar to Mixture-of-Experts (MoE) layers, each DMB layer consists of a set of N identical branches with different parameters. We also employ a lightweight gating unit to learn a probability distribution for activating each branch. Different from MoE layers, the gating unit only activates the branch with the highest probability.
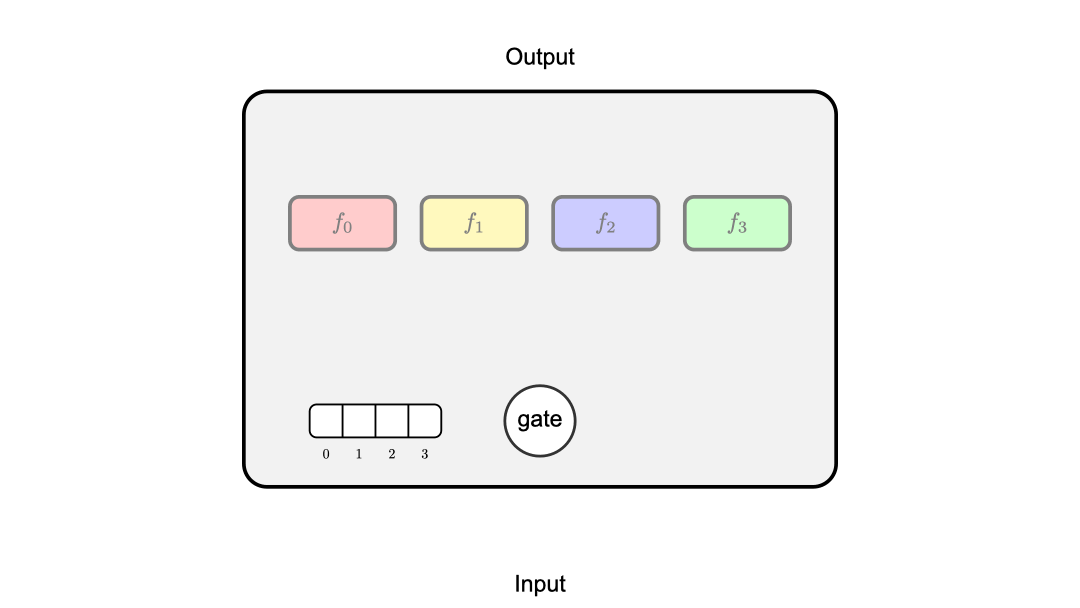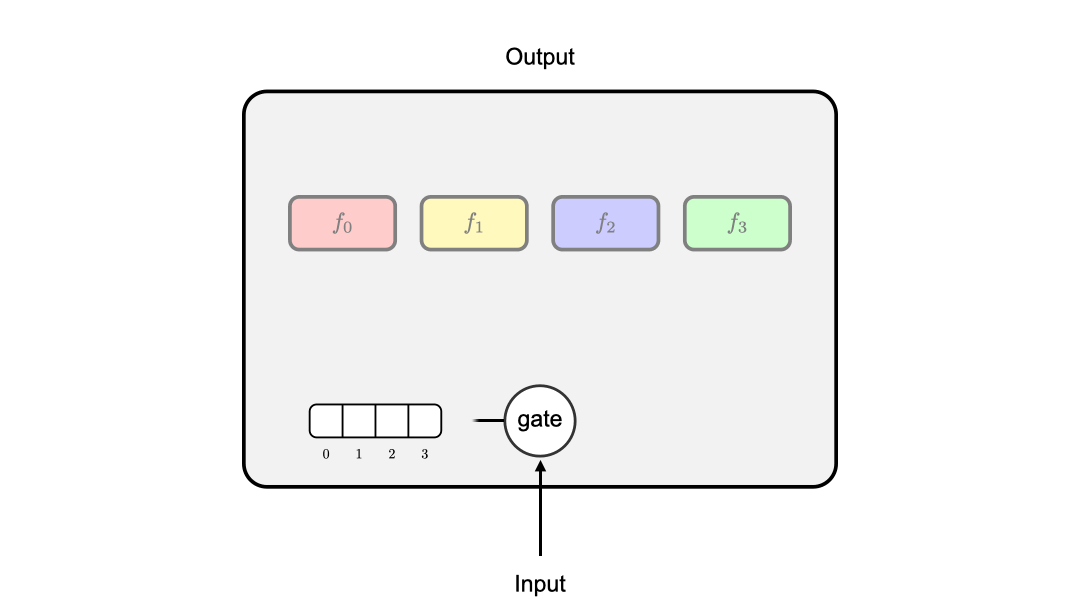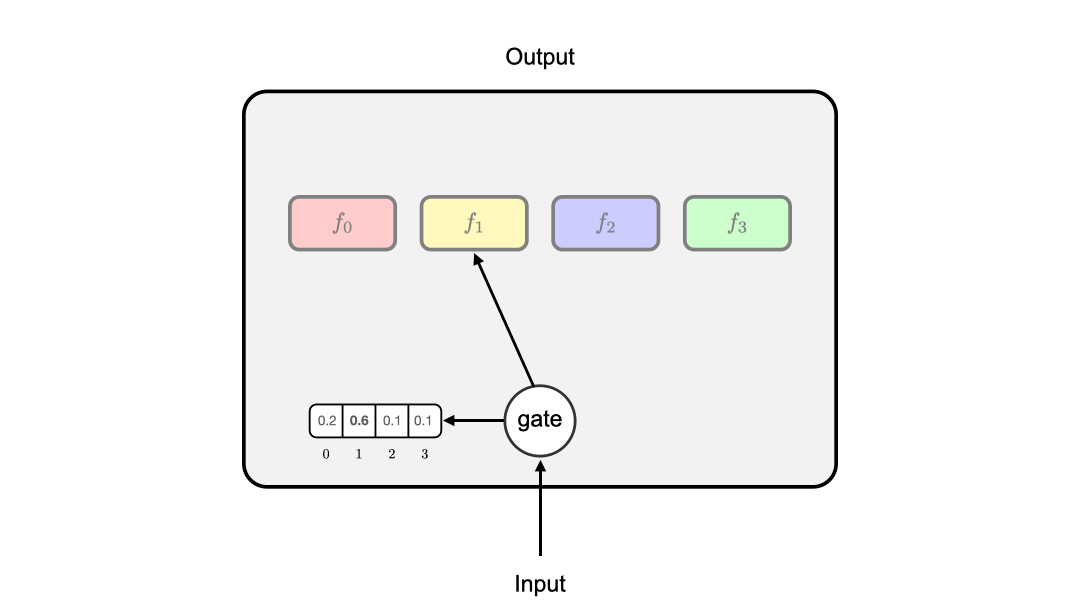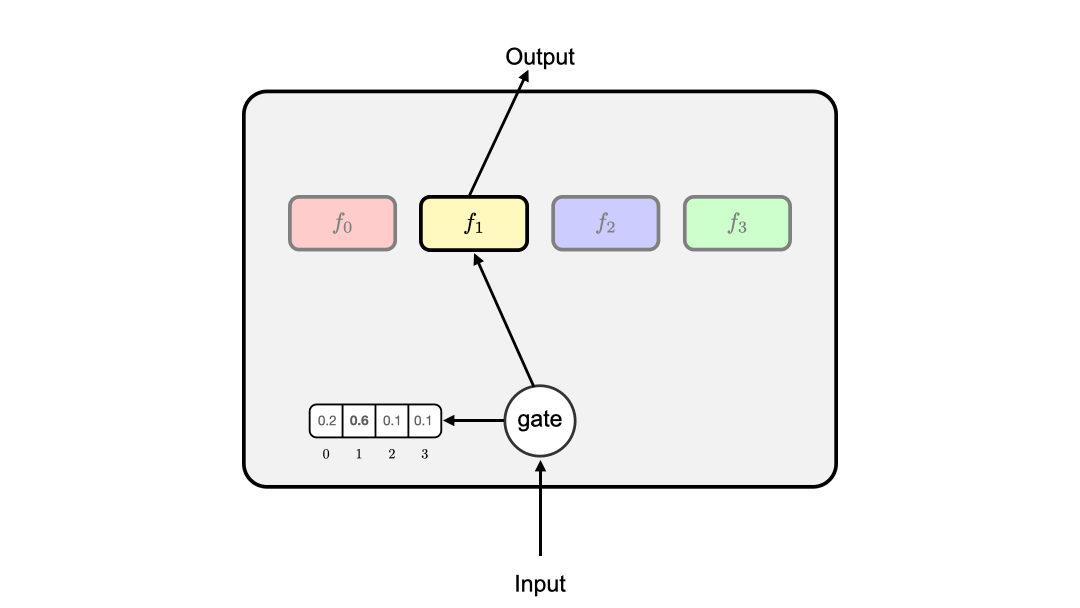
Figure 3 gives an illustration of a DMB layer. By introducing the gating unit, we can ensure that only one branch in a layer is active during training and inference. To enable the end-to-end training of gating units, we introduce two auxiliary losses:
- Diversity loss: A batch-level loss function. The goal of diversity loss is to encourage a balanced utilization of each branch.
- Entropy loss: A token-level loss function. We expect that the gating unit can give a high probability when activating a branch.
Shared-Private Reparameterization
Ideally, we expect a balanced utilization for all branches of a DMB layer. However, in this situation, each branch is only trained with a subset of training examples. We refer to this phenomenon as the shrinking training examples problem. For example, for a smaller training set or large choices of N, each branch is only trained with 1/N examples in expectation, which often leads to insufficient training of each branch.
To alleviate this problem, we propose a method called shared-private reparameterization: for a given DMB layer, the parameters of a branch in the DMB layer are reparameterized as shared parameters for all branches in the DMB layer plus private parameters that are bound to the branch. We can easily eliminate shared parameters after training. Therefore, there is zero computational and memory overhead after training when using shared-private reparameterization.
The Architecture
We extend the Transformer architecture with DMB layers, which we refer to as the Transformer-DMB architecture. We apply DMB at a more fine-grained level. Figure 4 depicts the Transformer-DMB architecture.

Experiments
We evaluate our proposed models on English-German (En-De) and Chinese-English (Zh-En) translation tasks. We experiment with two commonly used settings for on-device NMT:
- Tiny setting. We set the hidden size of the model to 128. The filter size of feed-forward layers is set to 512.
- Small setting. We set the hidden size of the model to 256. The filter size of feed-forward layers is set to 1024.

We report the inference latency of a sequence with 30 tokens in Table 5 on a Raspberry 4 device. For greedy search, the Transformer-DMB model costs about 7.7% more time than the Transformer model under the tiny model settings and costs about 10.9% more time under the small model settings. Compared with Transformer-MoE models, the TransformerDMB model is about 1.4 times faster under the tiny model settings, and 1.5 times faster under the small model settings. For beam search, Transformer-DMB modes introduce more computational burdens to Transformer models compared with the results when using greedy search. This is because our current implementation splits a batched matrix into smaller matrices to enable conditional computations, which reduces the degree of parallelism for matrix multiplications. We believe the gap can be significantly narrowed with a dedicated DMB-aware matrix multiplication kernel. You can find more experimental results in our paper.
Takeaway Message
We have proposed to use dynamic multi-branch layers to improve performance without sacrificing efficiency for on-device neural machine translation. This can be done by dynamically activating a single branch during training and inference. We also propose shared-private reparameterization for sufficient training of each branch. Experiments show that our approach achieves higher performance-time ratios than state-of-the-art approaches to on-device NMT.
Contact
For further discussion, please contact: Zhixing Tan(zxtan@tsinghua.edu.cn).