
In recent years, pre-trained language models (PLM) have shown tremendous success in natural language processing. By simply fine-tuning a pre-trained language model, the performance of many NLP tasks can be significantly improved.
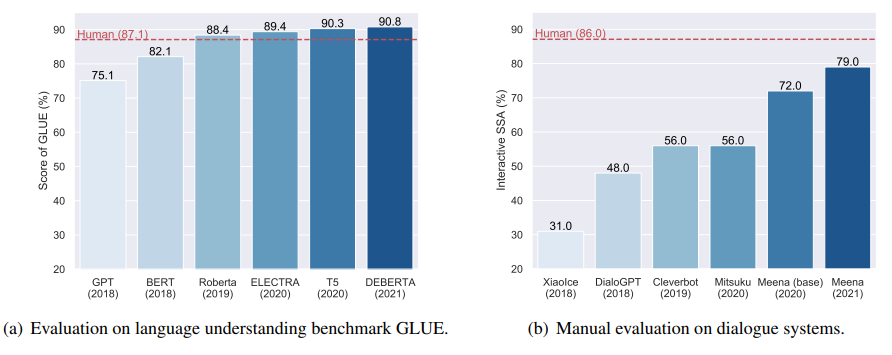
As the pre-trained LMs become more powerful, the model size of pre-trained LMs also becomes larger. For example, GPT-3 has 175B parameters. The huge model size makes the finetune paradigm impractical. Recently, prompting has emerged as an efficient way for applying pre-trained language models to downstream tasks. Prompting not only is parameter-efficient but is also modular, which opens the possibility of using a single LM to perform all NLP tasks.
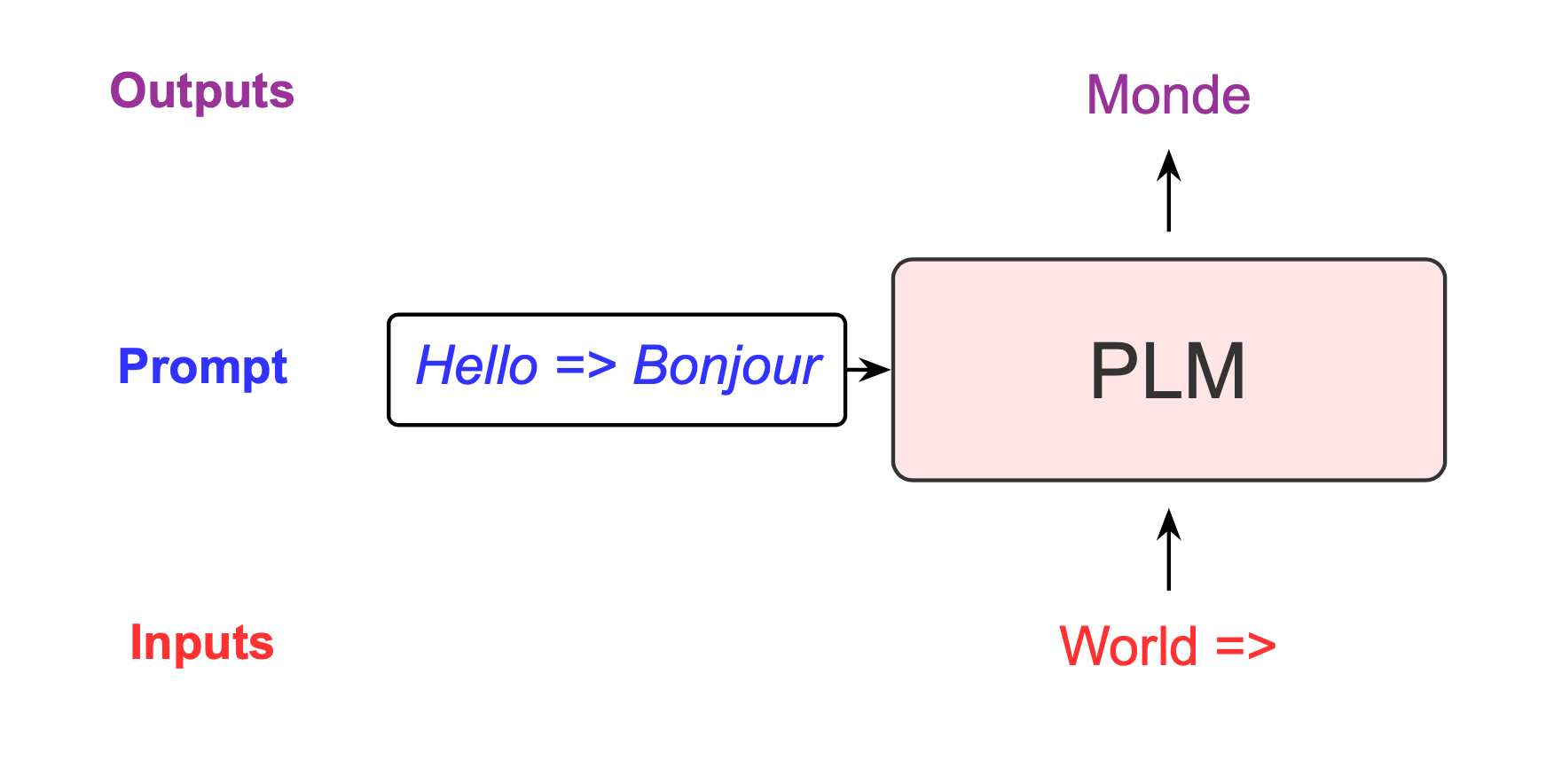
Machine translation (MT) is a challenging NLP task. While neural machine translation is the current de facto approach for machine translation, using pre-trained language models and prompting to perform translation tasks is appealing. For example, we can easily support a new translation task at a low memory cost. Furthermore, besides translation, the LM can retrain its ability to perform other NLP tasks.
However, leveraging pre-trained LMs for translation tasks via prompting faces many challenges. The first challenge is learning. It is not trivial to find an appropriate prompt for a translation task. The second challenge is training objective discrepancy. The third challenge is architectural differences. Generative LMs such as GPTs use a decoder-only architecture, which is unidirectional and may be sub-optimal for encoding source sentences.

To address these challenges, we propose multi-stage prompting in our recent ACL 2022 paper. The basic idea behind MSP is that we hope a complex task can be divided into many consecutive stages. By providing independent prompts at different stages, we expect the LM can learn a “smooth transition” to translation tasks.
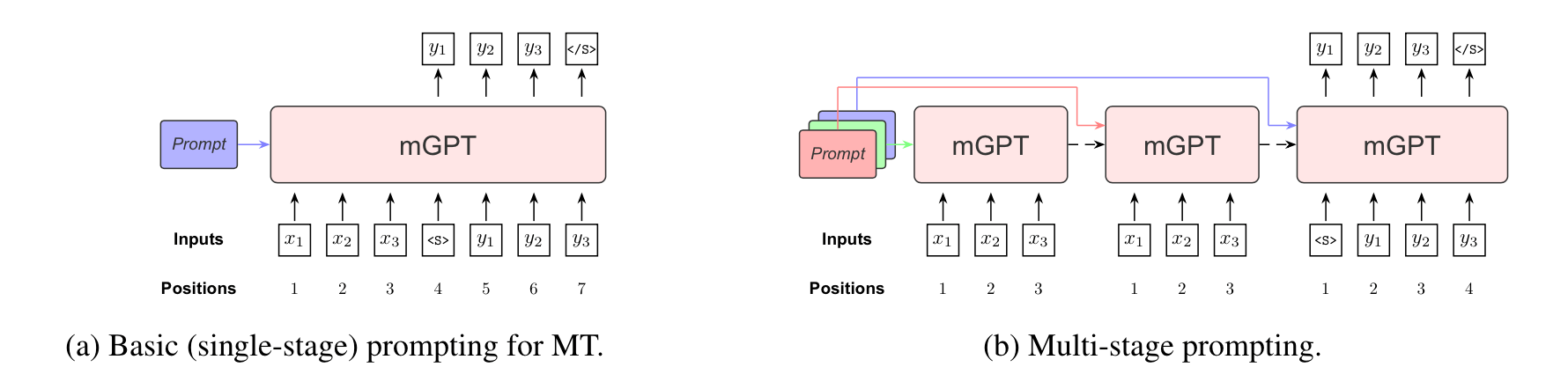
Multi-Stage Prompting
In our work, we use continuous prompts instead of textual prompts, which consist of continuous vectors. Similar to prefix-tuning, prompt vectors are prepended to all attention layers. These prompts are learned through back-propagation. The objective for learning prompts is cross-entropy loss, which is identical to NMT training. Note that we only tune prompt vectors, the pre-trained LMs are not tuned.
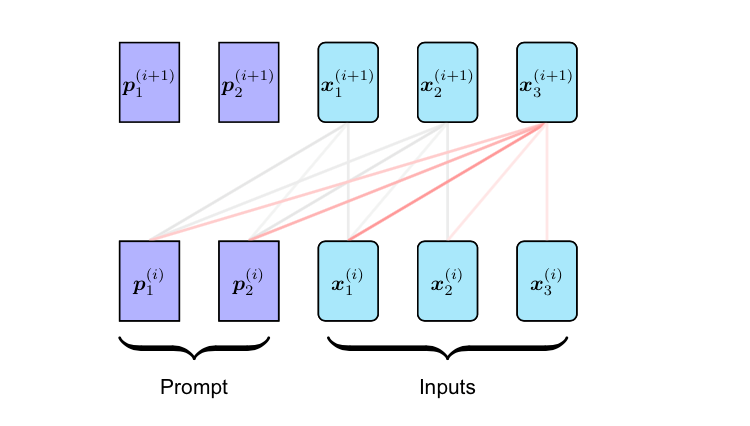
We design a three-stage scheme for MT tasks, which consists of an encoding stage, a re-encoding stage, and a decoding stage.

In the encoding stage, the pre-trained LM encodes the source sentence into a sequence of activations with an encoding stage prompt. In the re-encoding stage, the pre-trained LM produces fine-grained representations of the source sentence given past activations and a re-encoding stage prompt, allowing each representation to condition on all words. In the decoding stage, the LM predicts the probability of the target sentence given the refined source representations and a decoding stage prompt.
Following prefix-tuning, we also reparametrize prompt vectors. Instead of using MLPs, we introduce a simpler “scaled reparameterization”, which allows faster convergence. We introduce a tunable scalar so that the learning can be accelerated when the scalar value is larger than 1.0.
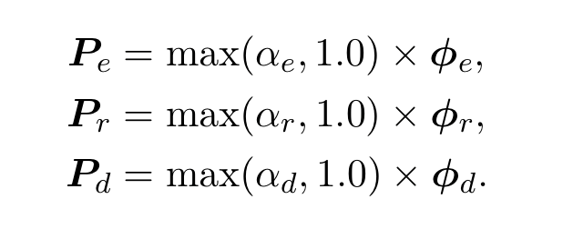
Experiments
We use mGPT, a multilingual version of GPT-2 for translation tasks for all our experiments. mGPT is trained on the mC4 dataset, which covers 101 languages. The model size of mGPT is about 560M parameters. We conduct experiments on three representative translation tasks: the WMT14 En-De translation task, the WMT16 Ro-En translation task, and the WMT20 En-Zh translation task. We compare our MSP with two prompting methods: prompt tuning and prefix tuning.
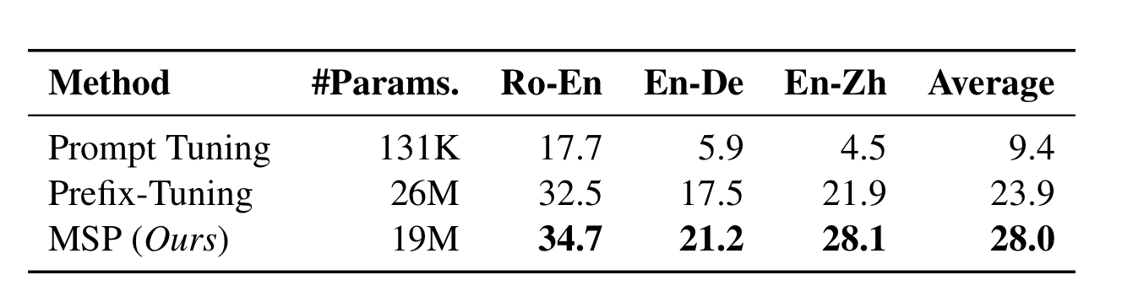
From table 1, we can see that prompt tuning is the most parameter-efficient method, which introduces only 131K parameters during training for each translation task. However, it only achieves 9.4 BLEU points on average over the three translation tasks because mGPT is not a huge LM, and model capacity is a key ingredient for prompt tuning to succeed. Prefix-tuning achieves an average of 23.9 BLEU points over the three translation tasks. The MLP network used in prefix-tuning introduces about 26M parameters for each translation task during training. MSP achieves 28.0 BLEU points on average over the three translation directions. MSP introduces 19M parameters for each translation task during training. The results suggest that MSP is more effective in instructing pre-trained LMs to perform translation than prompt tuning and prefix-tuning.
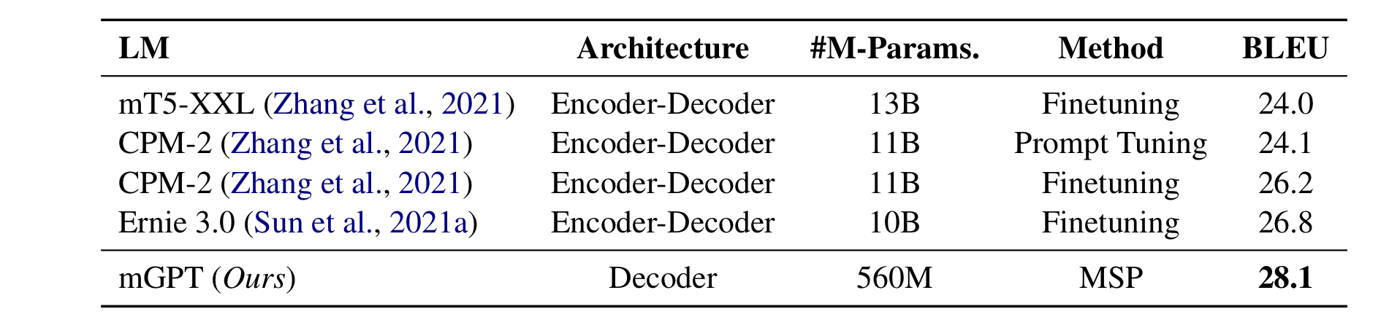
We compare mGPT with other LMs on the WMT20 En-Zh translation task in table 2. Except for mGPT, other LMs are based on the encoder-decoder architecture. Despite using a much smaller pre-trained LM with about 5% parameters of mT5-XXL, CPM-2, and Ernie 3.0, MSP achieves the best performance on the En-Zh translation task. Therefore, we show that MSP is an efficient and effective approach to steering pre-trained LMs to translation tasks.
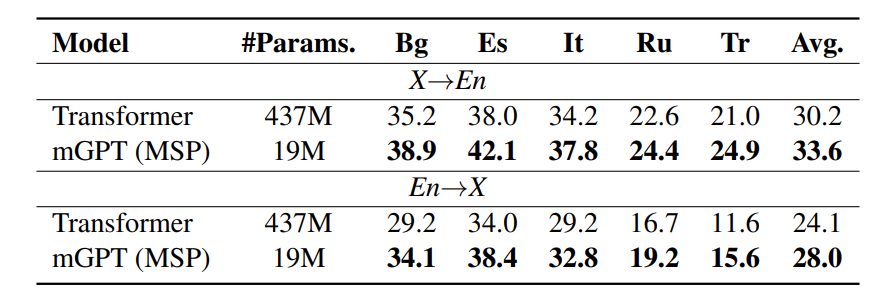
We compare our method with the Transformer model on the TedTalks dataset. TedTalks dataset is an English-centric multilingual corpus including 59 languages with around 3K to 200K sentence pairs per language pair. The Transformer model is trained on all available parallel sentences covering 59 languages. For mGPT with MSP, we individually train the model on each language pair. From table 3, we can see that mGPT with MSP outperforms the strong multilingual NMT baseline significantly on five selected language pairs. The results demonstrate that using pre-trained LMs as translators with an appropriate prompting method has the potential to outperform a strong Transformer NMT model. You can find more experimental results in our paper.
Takeaway Message
We have presented multi-stage prompting, a method for making pre-trained language models better translators. Experiments show that with multi-stage prompting, pre-trained LMs can generate better translations, showing the potential of using pre-trained LMs for translation tasks.
Contact
For further discussion, please contact: Zhixing Tan(zxtan@tsinghua.edu.cn).