
Introduction
Quality estimation (QE) of MT aims to evaluate the quality of the outputs of an MT system without references. Training QE models often requires massive parallel data with hand-crafted quality annotations. As obtaining such annotated data is time-consuming and labor-intensive in practice, unsupervised QE has received increasing attention.
Most of the previous unsupervised QE methods use various features to construct unsupervised models. These methods are simple and effective but limited to sentence-level tasks. Recently, Tuan et al. [1] use synthetic data to train unsupervised QE models, which can be applied for both sentence- and word-level tasks. However, this method may be negatively affected by the noise in the synthetic data. Moreover, The training process of this method is complex since it requires extra models to generate synthetic data.
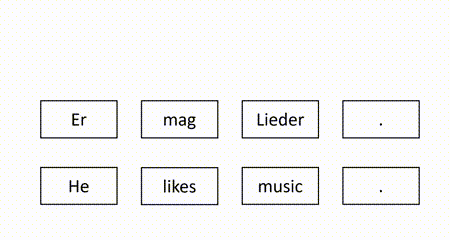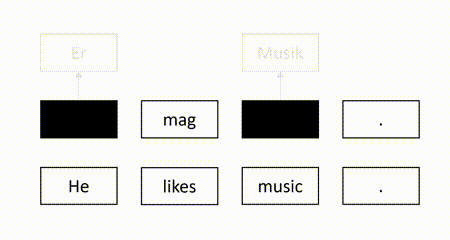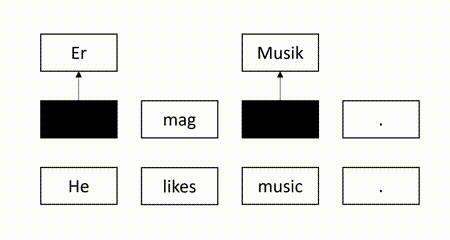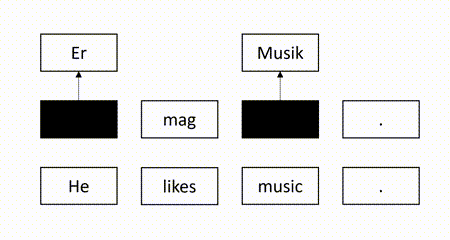
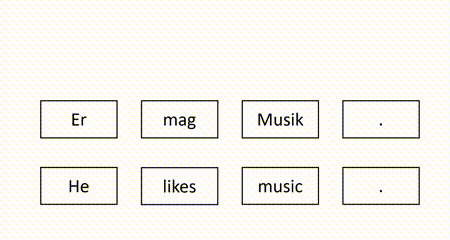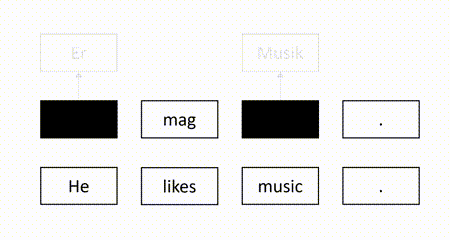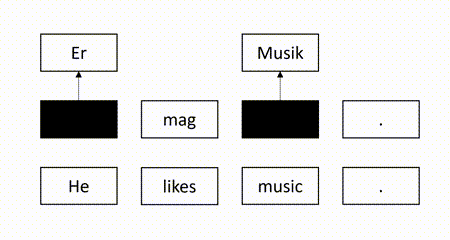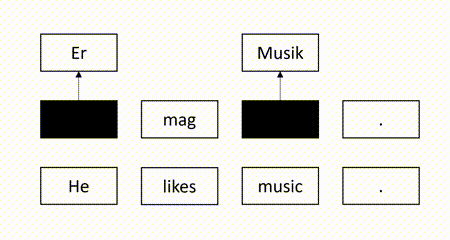
In our recent EMNLP 2021 paper, we propose a self-supervised QE method to overcome the aforementioned weaknesses. The basic idea is to mask some target words in the machine-translated sentence and use the source sentence and the observed target words to recover the masked target words. Intuitively, a target word is correct if it can be recovered according to its surrounding context. For example, in the figure below, since the masked target word “Er” can be successfully recovered but another masked target word “Lieder” is not identical to the recovered word “Musik”, we identify “Er” as correct and “Lieder” as erroneous.
Based on this intuition, our method estimates the translation quality of the target words by checking whether they can be correctly recovered. Finally, we obtain the sentence-level quality score by summarizing the word-level predictions. Obviously, our method is not affected by the noise and is easier to train, since it involves no synthetic data. Experimental results show that our self-supervised method outperforms previous unsupervised methods. Our code can be found here.
Model Architecture
As shown in the figure below, our self-supervised QE model is based on the multilingual BERT [2]. We use the concatenation of a source sentence and a partially masked target sentence as the input sequence and then use a Transformer encoder to recover the masked tokens. Similar to BERT [2], we mask 15% of the tokens in the target sentence.
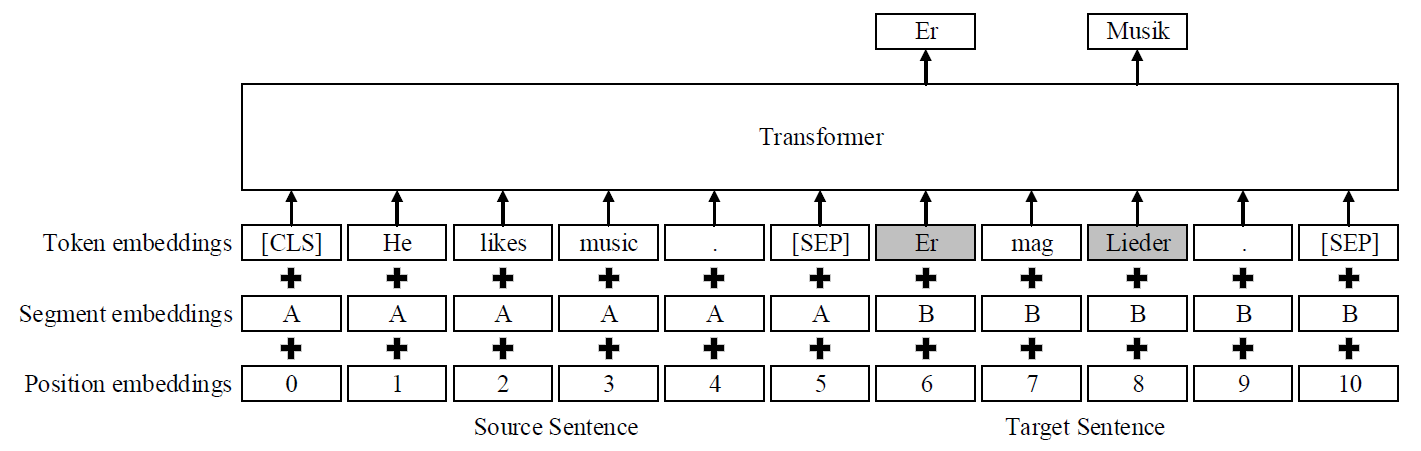
However, since the vocabulary of BERT is built with WordPiece [3], words in the input sequence may be divided into multiple subwords. Therefore, when a subword of a word with multiple subwords is masked, the model may easily recover the masked subword according to the remaining subwords without leveraging the source sentence. This is undesirable because the source sentence should play an important role in determining whether the token is correctly translated. To address this problem, we adopt a masking strategy called Whole Word Masking (WWM) [4], which forces all subwords of a word to be either masked or observed simultaneously.
Training and Inference
Our model is trained to recover the masked tokens in the target side of the authentic sentence pairs. Given a parallel corpus which consists of authentic sentence pairs, we divide each target sentence into the masked part and the observed part. We train the model to minimize the negative log-likelihood loss on the masked target tokens. The following figure illustrates the training process.
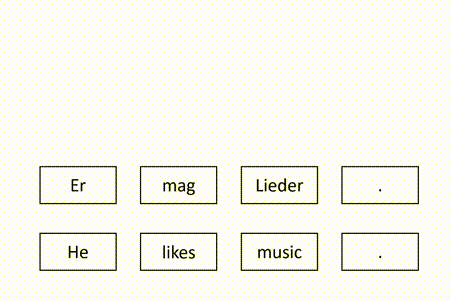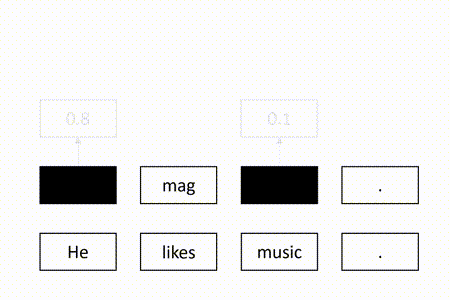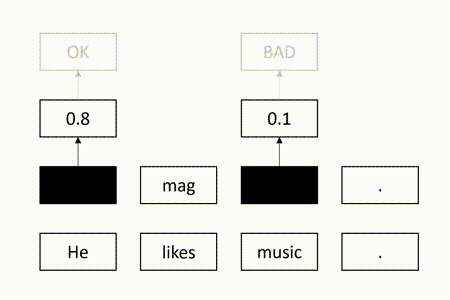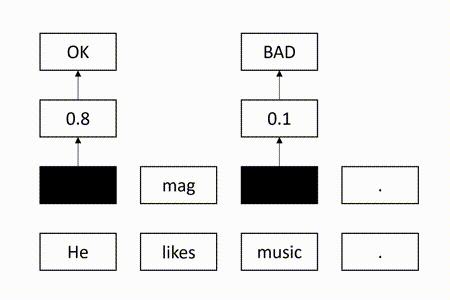
After the training process, we use the model to perform quality estimation by checking whether the masked target tokens can be successfully recovered. Specifically, for each masked token, we use the model to calculate the conditional probability of successful recovery. Obviously, the token is difficult to recover if the probability is low. In this case, we consider the token is erroneous. Otherwise, the token tends to be correct. Therefore, we regard the probability as the quality score of the token. If a threshold is given, we can map the score to a quality tag, as shown in the following:
Since the vocabulary is built with WordPiece [3], some of the input words may contain multiple subwords. In this case, we calculate the quality score of a target word with multiple subwords by simply averaging the quality scores of its subwords. Finally, we calculate the sentence-level quality score by averaging the quality scores over all target words.
To further improve the model’s performance, we also utilize Monte Carlo (MC) Dropout [5], which is used to extract model uncertainty, and proven conducive to the performance of unsupervised QE models [6].
Results
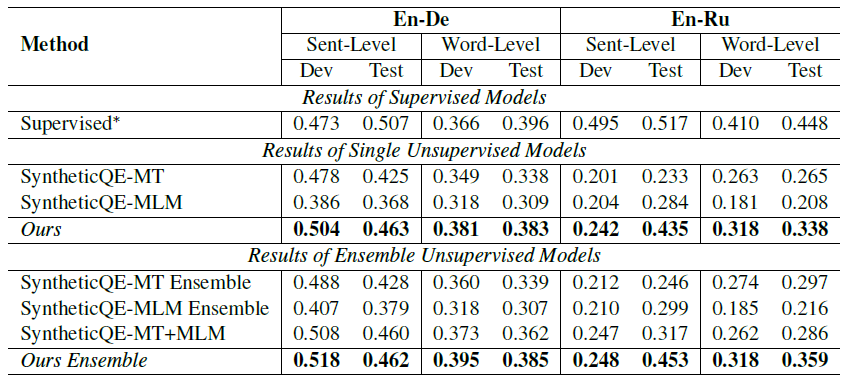
We mainly compare our method with different variants of SyntheticQE [1] on the WMT 2019 sentence- and word-level QE tasks. As shown in the table below, our method consistently outperforms SyntheticQE in both single model and ensemble model scenarios. You can find more results in our paper.
Case Study
To further show the advantages of our method, we provide an example in the table below. Erroneous target words annotated in the golden data or detected by the models are highlighted in red and italic. In this example, the only erroneous word in the target sentence is “Schnappschüsse”, which is corrected to “Schnappschüssen” in the post-edition. SyntheticQE-MT fails to detect this error, and wrongly predicts two correct words “gewünschten” and “finden” as erroneous. SyntheticQE-MLM also fails to detect this error. Our method successfully detects the error while it does not predict other correctly translated words as erroneous.

Conclusion and Future Work
We have presented a self-supervised method for quality estimation of machine-translated sentences. The central idea is to perform quality estimation by recovering masked target words using the surrounding context. Our method is easy to implement and is not affected by noisy synthetic data. Experimental results show that our method outperforms previous unsupervised QE methods. In the future, we plan to extend our self-supervised method to phrase- and document-level tasks. For further discussion, please contact: Yuanhang Zheng (zyh971025@126.com).
References
[1] Yi-Lin Tuan, Ahmed El-Kishky, Adithya Renduchintala, Vishrav Chaudhary, Francisco Guzmán, and Lucia Specia. Quality estimation without human-labeled data. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, 2021.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019.
[3] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Lukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, and Jeffrey Dean. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv: 1609.08144, 2016.
[4] Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, and Guoping Hu. Pre-training with whole word masking for chinese BERT. arXiv preprint arXiv: 1906.08101, 2019.
[5] Yarin Gal and Zoubin Ghahramani.Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the 33nd International Conference on Machine Learning, 2016.
[6] Marina Fomicheva, Shuo Sun, Lisa Yankovskaya, Frédéric Blain, Francisco Guzmán, Mark Fishel, Nikolaos Aletras, Vishrav Chaudhary, and Lucia Specia. Unsupervised quality estimation for neural machine translation. Transactions of the Association for Computational Linguistics, 8, 2020.