
Introduction
Multi-source sequence generation (MSG) is an important kind of sequence generation tasks that takes multiple sources, including automatic post-editing, multi-source translation, multi-document summarization, etc. MSG tasks face a severe challenge: there are no sufficient data to train MSG models. For example, multi-source translation requires parallel corpora involving multiple languages, which are usually restricted in quantity and coverage.
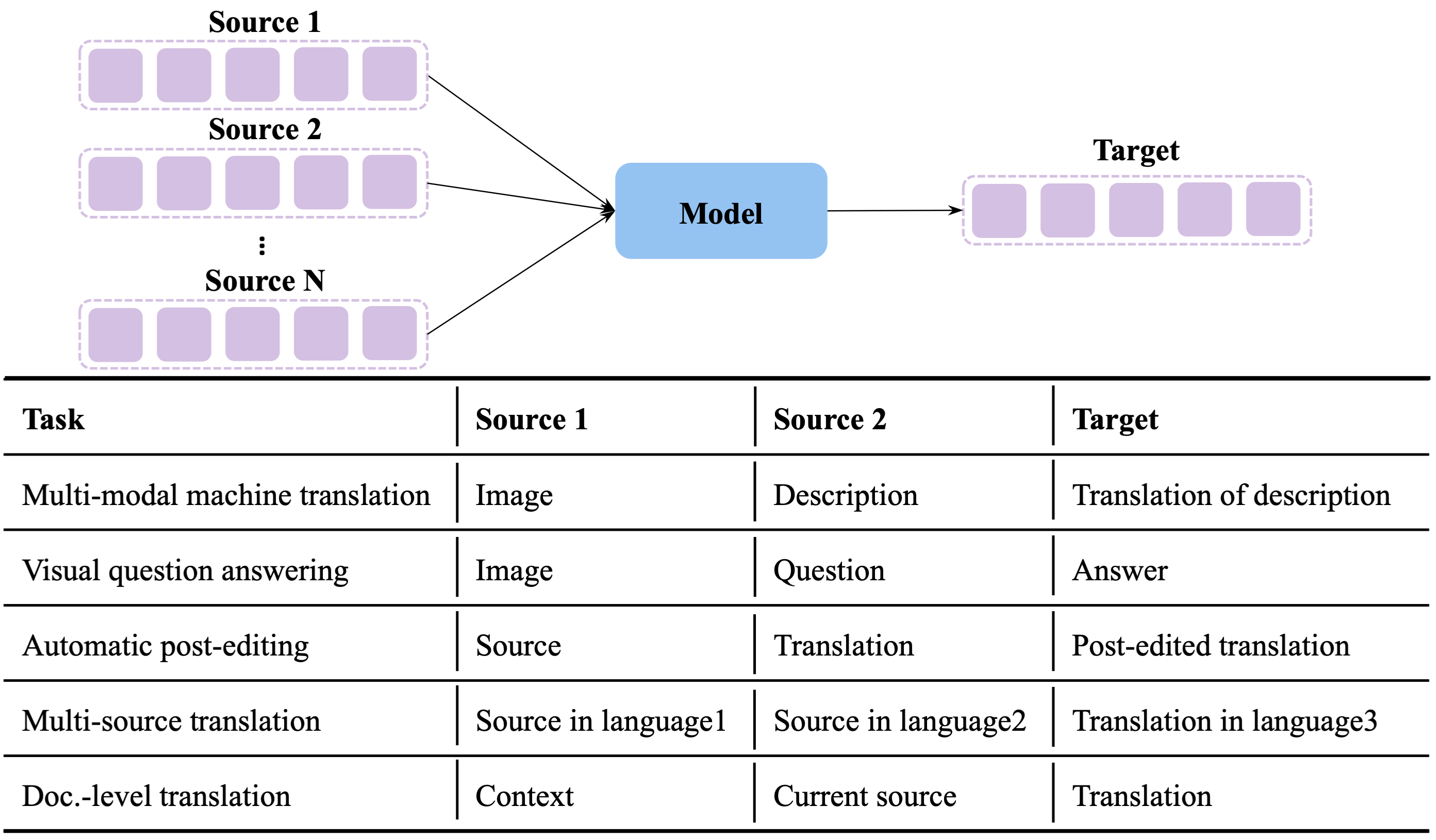
Recently, pretraining language models that take advantage of massive unlabeled data have proven to improve natural language understanding and generation tasks substantially. Although it is easy to transfer sequence-to-sequence (Seq2Seq) models to single-source sequence generation (SSG) tasks, transferring them to MSG tasks is challenging because MSG takes multiple sources as the input, leading to severe pretrain-finetune discrepancies in terms of both architectures and objectives.
A straightforward solution is to concatenate the representations of multiple sources and directly finetune the model for single-source generation on MSG tasks as suggested by Correia and Martins (2019). However, we believe this approach suffers from two major drawbacks: (1) directly transferring leads to catastrophic forgetting, (2) self-attention layers might not make full use of the cross-source information.
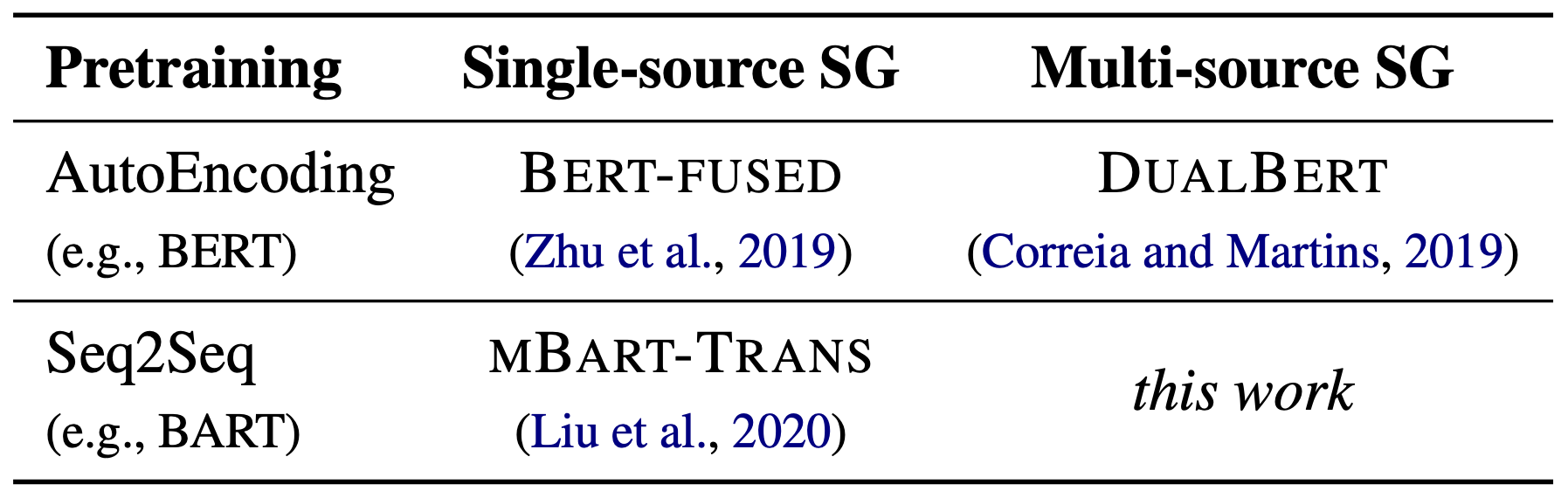
single-source and multi-source sequence generation tasks.
In our recent ACL 2021 paper, we propose a two-stage finetuning method named gradual finetuning. Different from prior studies, our work aims to transfer pretrained Seq2Seq models to MSG (see Table 1). Our approach first transfers from pretrained models to SSG and then transfers from SSG to MSG (see Figure 2). Furthermore, we propose a novel MSG model with coarse and fine encoders to differentiate sources and learn better representations. On top of a coarse encoder (i.e., the pretrained encoder), a fine encoder equipped with cross-attention layers is added.
We refer to our approach as TRICE (a task-agnostic Transferring fRamework for multI-sourCe sEquence generation), which achieves new state-of-the-art results on the WMT17 APE task and the multi-source translation task using the WMT14 test set. When adapted to document-level translation, our framework outperforms strong baselines significantly. You can find the code here.
Gradual Finetuning

We propose a two-stage finetuning method named gradual finetuning. The transferring process is divided into two stages (see Figure 2). In the first stage, the SSG model is transferred from denoising auto-encoding to the single-source sequence generation task, and the model architecture is kept the same with pretraining. In the second stage, an additional fine encoder is introduced to transform the SSG model to the MSG model, and the MSG model is optimized on the multi-source parallel corpus. From the perspective of data, during pretraining, large-scale unlabeled datasets are used. By contrast, during the first- and second-stage finetuning, single- and multi-source labeled datasets are used. Our approach can leverage medium-size single-source labeled datasets (e.g., parallel corpora used for machine translation) and alleviate pretrain-finetune discrepancies.
Model Architecture
The architecture of our framework is shown in Figure 3. In general, multiple sources are first concatenated and encoded by the coarse encoder and then encoded by the fine encoder to capture fine-grained cross-source information. Finally, the representations are utilized by the decoder to generate the target sentence. The modules highlighted in blue are trained on pretraining and the first finetuning stage. The modules highlighted in purple are randomly initialized at the beginning of the second finetuning stage.
Before the second finetuning step, the coarse encoder is used to encode different sources individually. As multiple sources are concatenated as a single source in which words interact by pretrained self-attentions, we conjecture that the cross-source information cannot be fully captured. Hence, we propose to add a randomly initialized fine encoder at the beginning of the second finetuning stage, which consists of self-attentions, cross-attentions, and FFNs, on top of the pretrained coarse encoder to learn meaningful multi-source representations. Specifically, the cross-attention sublayer is an essential part of the fine encoder because they perform fine-grained interactions between sources.
Experiments
We evaluated our framework on three MSG tasks: (1) automatic post-editing, (2) multi-source translation, and (3) document-level translation. For the APE task, we used the original WMT data for training in an extremely low-resource setting. We also adopt the pseudo data to evaluate our framework in a high-resource setting. According to the data scale, the multi-source translation and the document-level translation tasks can be seen as a medium-resource setting and a low-resource setting, respectively. Our approach shows strength against all baselines in all three tasks, with achieving new SOTA in the first two tasks.
In general, our framework shows a strong generalizability across three different MSG tasks and four different data scales, which indicates that it is useful to alleviate the pretrain-finetune discrepancy by gradual finetuning and learn multi-source representations by fully capturing cross-source information. You can find more experimental results in our paper.
Conclusion
We propose a novel task-agnostic framework, TRICE, to conduct transfer learning from single-source sequence generation including self-supervised pretraining and supervised generation to multi-source sequence generation. With the help of the proposed gradual finetuning method and the novel MSG model equipped with coarse and fine encoders, our framework outperforms all baselines on three different MSG tasks in four different data scales, which shows the effectiveness and generalizability of our framework.
Contact
For further discussion, please contact: Xuancheng Huang (xchuang17@163.com).